

It will greatly aid your thinking about storage engines and the capabilities they bring to MySQL if you have a good mental picture of where they fit. Figure 1 provides a logical view of MySQL. It doesn't necessarily reflect the low-level implementation, which is bound to be more complicated and less clear cut. However, it does serve as a guide that will help you understand how storage engines fit in to MySQL. (The NDB storage engine was added to MySQL just before this book was printed. Watch for it in the second edition.)
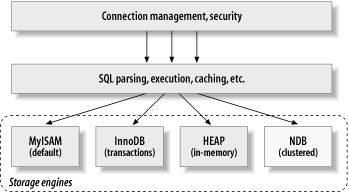
Figure 1 - A logical view of MySQL's architecture
The topmost layer is composed of the services that aren't unique to MySQL. They're services most network-based client/server tools or servers need: connection handling, authentication, security, etc.
The second layer is where things get interesting. Much of the brains inside MySQL live here, including query parsing, analysis, optimization, caching, and all the built-in functions (dates, times, math, encryption, etc.). Any functionality provided across storage engines lives at this level. Stored procedures, which will arrive in MySQL 5.0, also reside in this layer.
The third layer is made up of storage engines. They're responsible for the storage and retrieval of all data stored "in" MySQL. Like the various filesystems available for Linux, each storage engine has its own benefits and drawbacks. The good news is that many of the differences are transparent at the query layer.
The interface between the second and third layers is a single API not specific to any given storage engine. This API is made up of roughly 20 low-level functions that perform operations such as "begin a transaction" or "fetch the row that has this primary key" and so on. The storage engines don't deal with SQL or communicate with each other; they simply respond to requests from the higher levels within MySQL.
Locking and Concurrency
The first of those problems is how to deal with concurrency and locking. In any data repository you have to be careful when more than one person, process, or client needs to change data at the same time. Consider, for example, a classic email box on a Unix system. The popular mbox file format is incredibly simple. Email messages are simply concatenated together, one after another. This simple format makes it very easy to read and parse mail messages. It also makes mail delivery easy: just append a new message to the end of the file.
But what happens when two processes try to deliver messages at the same time to the same mailbox? Clearly that can corrupt the mailbox, leaving two interleaved messages at the end of the mailbox file. To prevent corruption, all well-behaved mail delivery systems implement a form of locking to prevent simultaneous delivery from occurring. If a second delivery is attempted while the mailbox is locked, the second process must wait until it can acquire the lock before delivering the message.
This scheme works reasonably well in practice, but it provides rather poor concurrency. Since only a single program may make any changes to the mailbox at any given time, it becomes problematic with a high-volume mailbox, one that receives thousands of messages per minute. This exclusive locking makes it difficult for mail delivery not to become backlogged if someone attempts to read, respond to, and delete messages in that same mailbox. Luckily, few mailboxes are actually that busy.
Read/Write Locks
Reading from the mailbox isn't as troublesome. There's nothing wrong with multiple clients reading the same mailbox simultaneously. Since they aren't making changes, nothing is likely to go wrong. But what happens if someone tries to delete message number 25 while programs are reading the mailbox? It depends. A reader could come away with a corrupted or inconsistent view of the mailbox. So, to be safe, even reading from a mailbox requires special care.
Database tables are no different. If you think of each mail message as a record and the mailbox itself as a table, it's easy to see that the problem is the same. In many ways, a mailbox is really just a simple database table. Modifying records in a database table is very similar to removing or changing the content of messages in a mailbox file.
The solution to this classic problem is rather simple. Systems that deal with concurrent read/write access typically implement a locking system that consists of two lock types. These locks are usually known as shared locks and exclusive locks or read locks and write locks.
Without worrying about the actual locking technology, we can describe the concept as follows. Read locks on a resource are shared: many clients may read from the resource at the same time and not interfere with each other. Write locks, on the other hand, are exclusive, because it is safe to have only one client writing to the resource at given time and to prevent all reads when a client is writing. Why? Because the single writer is free to make any changes to the resource—even deleting it entirely.
In the database world, locking happens all the time. MySQL has to prevent one client from reading a piece of data while another is changing it. It performs this lock management internally in a way that is transparent much of the time.
Lock Granularity
One way to improve the concurrency of a shared resource is to be more selective about what is locked. Rather than locking the entire resource, lock only the part that contains the data you need to change. Better yet, lock only the exact piece of data you plan to change. By decreasing the amount of data that is locked at any one time, more changes can occur simultaneously—as long as they don't conflict with each other.
The downside of this is that locks aren't free. There is overhead involved in obtaining a lock, checking to see whether a lock is free, releasing a lock, and so on. All this business of lock management can really start to eat away at performance because the system is spending its time performing lock management instead of actually storing and retrieving data. (Similar things happen when too many managers get involved in a software project.)
To achieve the best performance overall, some sort of balance is needed. Most commercial database servers don't give you much choice: you get what is known as row-level locking in your tables. MySQL, on the other hand, offers a choice in the matter. Among the storage engines you can choose from in MySQL, you'll find three different granularities of locking. Let's have a look at them.
Table locks
The most basic and low-overhead locking strategy available is a table lock, which is analogous to the mailbox locks described earlier. The table as a whole is locked on an all-or-nothing basis. When a client wishes to write to a table (insert, delete, or update, etc.), it obtains a write lock that keeps all other read or write operations at bay for the duration of the operation. Once the write has completed, the table is unlocked to allow those waiting operations to continue. When nobody is writing, readers obtain read locks that allow other readers to do the same.
For a long time, MySQL provided only table locks, and this caused a great deal of concern among database geeks. They warned that MySQL would never scale up beyond toy projects and work in the real world. However, MySQL is so much faster than most commercial databases that table locking doesn't get in the way nearly as much as the naysayers predicted it would.
Part of the reason MySQL doesn't suffer as much as expected is because the majority of applications for which it is used consist primarily of read queries. In fact, the MyISAM engine (MySQL's default) was built assuming that 90% of all queries run against it will be reads. As it turns out, MyISAM tables perform very well as long as the ratio of reads to writes is very high or very low.
Page locks
A slightly more expensive form of locking that offers greater concurrency than table locking, a page lock is a lock applied to a portion of a table known as a page. All the records that reside on the same page in the table are affected by the lock. Using this scheme, the main factor influencing concurrency is the page size; if the pages in the table are large, concurrency will be worse than with smaller pages. MySQL's BDB (Berkeley DB) tables use page-level locking on 8-KB pages.
The only hot spot in page locking is the last page in the table. If records are inserted there at regular intervals, the last page will be locked frequently.
Row locks
The locking style that offers the greatest concurrency (and carries the greatest overhead) is the row lock. In most applications, it's relatively rare for several clients to need to update the exact same row at the same time. Row-level locking, as it's commonly known, is available in MySQL's InnoDB tables. InnoDB doesn't use a simple row locking mechanism, however. Instead it uses row-level locking in conjunction with a multiversioning scheme, so let's have a look at that.
Multi-Version Concurrency Control
There is a final technique for increasing concurrency: Multi-Version Concurrency Control (MVCC). Often referred to simply as versioning, MVCC is used by Oracle, by PostgreSQL, and by MySQL's InnoDB storage engine. MVCC can be thought of as a new twist on row-level locking. It has the added benefit of allowing nonlocking reads while still locking the necessary records only during write operations. Some of MVCC's other properties will be of particular interest when we look at transactions in the next section.
So how does this scheme work? Conceptually, any query against a table will actually see a snapshot of the data as it existed at the time the query began—no matter how long it takes to execute. If you've never experienced this before, it may sound a little crazy. But give it a chance.
In a versioning system, each row has two additional, hidden values associated with it. These values represent when the row was created and when it was expired (or deleted). Rather than storing the actual time at which these events occur, the database stores the version number at the time each event occurred. The database version (or system version) is a number that increments each time a query[1] begins. We'll call these two values the creation id and the deletion id.
[1] That's not quite true. As you'll see when we start talking about transactions later, the version number is incremented for each transaction rather than each query.
Under MVCC, a final duty of the database server is to keep track of all the running queries (with their associated version numbers). Let's see how this applies to particular operations:
SELECT
When records are selected from a table, the server must examine each row to ensure that it meets several criteria:
- Its creation id must be less than or equal to the system version number. This ensures that the row was created before the current query began.
- Its deletion id, if not null, must be greater than the current system version. This ensures that the row wasn't deleted before the current query began.
- Its creation id can't be in the list of running queries. This ensures that the row wasn't added or changed by a query that is still running.
- Rows that pass all of these tests may be returned as the result of the query.
INSERT
- When a row is added to a table, the database server records the current version number along with the new row, using it as the row's creation id.
DELETE
- To delete a row, the database server records the current version number as the row's deletion id.
UPDATE
- When a row is modified, the database server writes a new copy of the row, using the version number as the new row's creation id. It also writes the version number as the old row's deletion id.
